Bruno Pedro
GraphQL: 3 reasons not to use it
This post was originally published on the Hitch blog as “GraphQL: 3 reasons not to use it”. GraphQL is a query language created by Facebook in 2012. Its purpose is to describe the capabilities and requirements of data models for client-server applications. Facebook has been using GraphQL ever since and it has been open sourced in 2015. Its specification is evolving in the form of a Draft RFC.
The primary motivation to create GraphQL was that, according to Lee Byron, Facebook “started with a system that looked a lot like a traditional RESTful server but found it difficult to use as iOS developers, and saw conflict between the desire to load all information in a single round trip while keeping REST resources well isolated.”
It’s interesting to notice what their primary motivation was. They wanted to be able to let API consumers access all the information without making any changes to backend code. This can only be achieved by making API consumers aware of the data model driving the application and breaking one of the most important principles of software design: information hiding.
1—GraphQL does not offer information hiding #
Modern applications usually consume or interact with third-party modules and APIs. Neither the developer nor the application needs to have knowledge of how those third parties work internally. “Hiding” those details is considered a Software Development best practice.
Information hiding is commonly known as the “ability to prevent certain aspects of a software component from being accessible to its clients.” Furthermore, “a common use of information hiding is to hide the layout for data so that if it is changed, the change is restricted”.
The main advantage of APIs is that they allow application and system developers, primarily, to carry out information hiding which is an approach in which implementation details are hidden from other modules. — Huerta & Childs, 2015
The importance of following this principle grows with the number of developers accessing your API. Hiding implementation details from API consumers decreases the dependency among developers, thus simplifying coordination and support (de Souza & Redmiles, 2009).
GraphQL passes the burden of understanding the system data schema to client application developers. By design, a developer who integrates against GraphQL needs to know the names of the fields to access, their relation to other objects and when to retrieve them.
While this might not be a challenge for developers that work closely with the API provider, it might have profound implications for all the other developers that are just trying to start using our API.
It also creates a strong coupling between the API provider and all its clients. If the data model changes in some way, all the API clients will have to update their code in numerous places. This could very easily be avoided if GraphQL provided a way to version requests, but it doesn’t.
2—GraphQL is not versioned #
It is generally accepted that any API changes over time. Twitter API, for instance, introduces on average about 20 changes per month. Without versioning, integrating against an API is at best an act of faith because you’ll never know when your application will stop working due to some breaking change.
Especially when the client developers have no control over when changes happen to the web API behavior, versioning that behavior allows the client developers to know what behavior to expect from a particular web API. Versioning (…) allows client developers to know when to expect changes — Espinha et al, 2015
Some of the common changes might be related to new endpoints but they might also include removed or replaced request parameters and response fields. This totally changes the API consumer assumptions of what the data model is and how it behaves. Deprecating some part of an API shouldn’t be done simply at a functional level. Versioning helps deprecating APIs because it gives developers time to upgrade.
APIs were deprecated as part of a versioning strategy that sought to move developers wholesale to a more updated version of the API. Yelp, Facebook, and eBay all stressed the availability of migration pathways to help existing developer consumers make the switch. — Boyd, 2016
By design, GraphQL does not offer versioning. Instead, it lets API providers define certain fields as deprecated. According to its specification, “fields and enum values can indicate whether or not they are deprecated and a description of why it is deprecated”. But how will developers know if their applications need to be rewritten to accommodate the changes?
The only hint developers get is when they’re building their integrations and see the deprecated fields or, even worse, stop seeing some of the fields they used to before.
What about default behavior change? There simply is no way to know if a field’s default value has changed over time. While this might seem of low importance, it might lead to breaking changes and repeated failures from API clients which are hard to track and debug.
Again, by not offering the ability to version an API, GraphQL passes the burden of understanding the data model to integration developers. An interesting side-effect of not offering versioning is the added difficulty to cache responses and avoid multiple requests that grab the same data.
3—GraphQL responses cannot be safely cached #
Cache can be described as the storage of “data so future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation, or the duplicate of data stored elsewhere.” So, the goal of caching an API response is primarily to obtain the response from future requests faster.
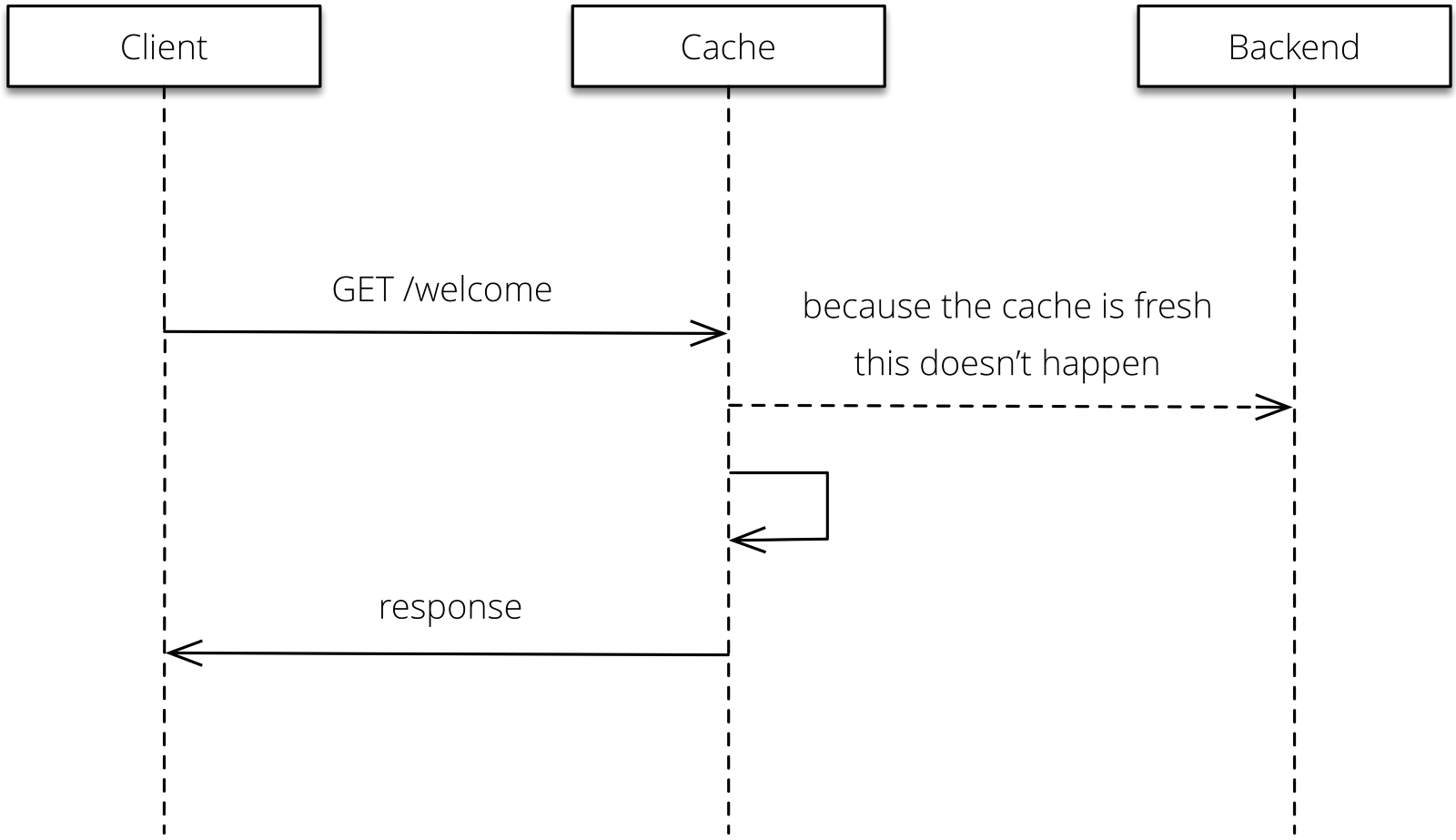
The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases, and to eliminate the need to send full responses in many other cases. The former reduces the number of network round-trips required for many operations (…). The latter reduces network bandwidth requirements — Fielding et al, 1999
The existence of caching also lets API providers take advantage of Content Delivery Networks (CDNs) to decrease latency between clients and servers while increasing availability and performance. Without HTTP caching, CDNs wouldn’t even be able to exist.
But caching can also be performed at the application layer. In this case, developers need to build the logic to save information locally and expire it according to their needs. This is exactly what GraphQL promotes, leaving the potential usage of HTTP caching and CDNs out.
According to the GraphQL documentation, in order to let developers implement client caching, it’s “a best practice for the API to expose globally unique IDs for objects”. It is left to developers to figure out how to save the information locally and when to expire it.
What happens then, when some of the fields on a response become deprecated? For how long should a client hold its version of a response on its internal cache? With HTTP and versioning, these would not constitute a problem but the same cannot be said of GraphQL.
The burden is, yet again, passed to the hands of integration developers. Let’s put things in perspective and think about a mobile application used by millions of people. How would you remotely expire existing cache data on all those devices?
Conclusion #
While GraphQL seems to bring many advantages to the world of Web APIs, it poses several risks to both API providers and consumers. This article described three potential pitfalls you’d want to avoid when dealing with Web APIs.
Firstly, the lack of information hiding makes integration developers responsible for understanding how the API behaves. Secondly, the lack of versioning makes it difficult to plan for changes and manage eventual code migrations. Lastly, not being able to safely cache responses increases the number of calls a client needs to perform.
GraphQL might be a good enough solution for many scenarios but it certainly is not a replacement for the best practices that we developers have become accustomed to: support for information hiding, versioned endpoints and being able to safely cache responses.